

大數據簡介
用于分析過去以便進行未來預測的大型數據集稱為大數據。它們的主要概念是體積、速度和多樣性,因此任何數據都很容易處理。結構化和非結構化數據都會被處理,這不是使用傳統的數據處理方法來完成的。它從數據處理流中為任何人提供所需的信息。它被用于研究、分析、醫療領域、教育以及處理海量數據的地方。它是從社交媒體、機器數據和事務數據演變而來的。

什么是大數據
下面的文章為大數據的介紹提供了一個提綱。傳統的數據處理無法處理龐大而復雜的數據。因此,我們使用大數據來分析、提取信息,更好地理解數據。我們考慮體積,速度,多樣性,準確性和價值的大數據。大數據的一個例子是通過社交媒體生成的人的數據。大數據有助于分析數據中的模式,以便輕松理解人們和企業的行為。這有助于高效處理,從而提高客戶滿意度。大數據中涉及的數據可以是結構化的或非結構化的,也可以是自然的或經過處理的,或者與時間有關。
大數據的主要組成部分
以下是大數據的主要組成部分:
Hadoop、數據科學、統計和;其他
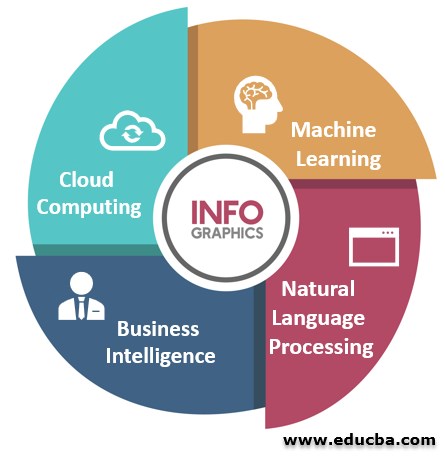
1。機器學習
這是一門讓計算機自己學習的科學。在機器學習中,計算機需要使用算法和統計模型來執行特定的任務,而不需要任何明確的指令。機器學習應用程序提供基于過去經驗的結果。例如,現在有一些移動應用程序可以為你提供財務、賬單的摘要,提醒你賬單的支付情況,還可以為你提供一些儲蓄計劃的建議。這些功能是通過閱讀電子郵件和短信來完成的。
2。自然語言處理(NLP)
它是計算機理解人類語言的能力。現在人們能想到的最明顯的例子是谷歌主頁和亞馬遜Alexa。兩者都使用NLP和其他技術為我們提供虛擬助手體驗。NLP就在我們身邊,我們甚至都沒有意識到。在寫郵件時,如果出現任何錯誤,它會自動更正自己,現在它會自動給出完成郵件的建議,并在我們試圖發送一封沒有電子郵件文本中引用的附件的電子郵件時自動恐嚇我們,這是在后端運行的自然語言處理應用程序的一部分。
3。商業智能
商業智能(BI)是一種技術驅動的方法或流程,通過分析數據并以最終用戶(通常是高層管理人員)如經理和企業領導人可以從中獲得一些可操作的見解并對其做出明智的商業決策的方式來獲取見解。
4。云計算
如果我們按名稱來命名,它應該是在云上進行計算的;嗯,這是真的,這里我們不是在談論真正的云,這里的云是互聯網的參考。因此,我們可以將云計算定義為提供計算服務——服務器、存儲、數據庫、網絡、軟件、分析、智能,以及互聯網(“云”),以提供更快的創新、靈活的資源和規模經濟。
大數據的特點
以下是大數據的特點:
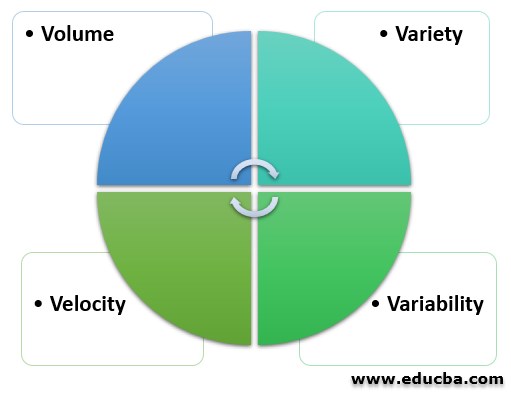
- 體積:為了確定數據的價值,需要考慮數據的大小,這一點至關重要。此外,為了確定特定類型的數據是否屬于“大數據導論”類別,它取決于數據量</李>
- 多樣性:多樣性是指根據數據的性質(結構化和非結構化)不同的數據類型。之前,大多數應用程序考慮的唯一數據源是行和列的形式,它們通常以電子表格和數據庫的形式出現。但如今,數據以我們能想象的任何形式出現,比如電子郵件、照片、視頻、音頻等等</李>
- 速度:速度,顧名思義,是數據生成的速度。從一個來源來看,數據生成的速度和處理的速度決定了數據的潛力</李>
- 可變性:數據可能是可變的,這意味著它可能不一致,而不是在流程中,從而干擾或成為以有效方式處理和管理數據的障礙</李>
大數據的應用
大數據分析的使用方式如下:
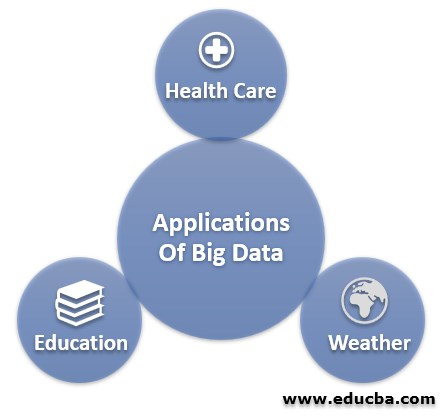
- 醫療:我們現在有可穿戴設備和傳感器,可以實時更新患者的健康狀況</李>
- 教育:通過大數據分析進行適當分析,可以跟蹤和改進學生的進步</李>
- 天氣:部署在全球各地的天氣傳感器和衛星收集大量數據,并使用這些數據監測天氣和環境狀況,還預測或預測未來幾天的天氣狀況</李>
大數據的優缺點
以下是優點和缺點:
</t車身>
| 優勢 | 缺點 |
| 更好的決策 | 數據質量:數據質量需要良好,并安排好進行大數據分析 |
| 提高生產力 | 硬件需求:需要存儲數據的存儲空間,以及在分析系統之間傳輸數據所需的網絡帶寬,這些都是購買和維護大數據環境的昂貴成本 |
| 降低成本 | 網絡安全風險:存儲敏感和大量數據會使公司成為網絡攻擊者更具吸引力的目標,網絡攻擊者可能會將數據用于勒索或其他不法目的 |
| 改善客戶服務 | 在與傳統系統集成方面遇到了困難:許多長期經營的老企業在不同的體系結構和環境中,將數據存儲在不同的應用程序和系統中。這在整合過時的數據源和移動數據方面產生了問題,進一步增加了處理大數據的時間和費用 |
理解V
以下是提到的理解:
Hadoop、數據科學、統計和;其他
1。音量
處理和處理大量數據是一個常見問題。它利用Hadoop、Apache Spark和HDFS等其他技術輕松地執行任務。
2。速度
組織高速收集數據以處理即時結果。它可以應對這種情況,提供無縫的處理和結果。股票交易所和天氣預報就是一些實時的例子。
3。多樣性
- 結構化:從關系數據庫派生的預設格式的數據集。例如,一個員工的工資表上有一個預定義的模式</李>
- 非結構化:這些是沒有正確格式或對齊的隨機數據。因此,它們需要更多的處理時間。例如谷歌搜索、社交媒體民意調查、視頻流</李>
- 半結構化:它是結構化和非結構化數據的組合。它們有適當的結構,但缺乏所需的定義</李>
如何使工作變得更容易
在此之前,對現有數據進行了線性和逐行分析。后來隨著計算機的引入,Excel電子表格使生活變得簡單。用戶需要將不同的記錄制成表格,并進行必要的研究,以得出有意義的報告。它在許多方面改變了游戲規則。可以處理和分析高達TB的大量數據集。應用了復雜的查詢和算法。生成的報告具有更好的結果,幾乎沒有失敗。所有這些都需要幾分鐘到幾小時的時間,這取決于數據的大小。
頂級公司
它被廣泛應用于制造業、醫療保健、能源、保險、體育等領域。一些頂級公司如下所示:
- IBM
- 微軟
- 亞馬遜
- 惠普企業
- Teradata
組成部分
下面列出了各種第三方工具,可用于對來源提供的數據進行分析。它們可以獨立運行,也可以與其他組件協作。
- Hadoop
- HDFS
- Sqoop
- 地圖縮小
- 阿帕奇星火/風暴
- 谷歌大查詢
- 亞馬遜運動
用例
- 管理層可以做出更好的決策</李>
- 識別客戶需求的趨勢并保持相關性</李>
- 低風險結果</李>
- 決策驗證</李>
- 確定了目標受眾</李>
工作
借助Hadoop等第三方工具,Spark可以將大型數據集加載到外部存儲。數據是基于人工編寫的查詢進行處理的。商業智能團隊利用這些報告來理解預測模式并糾正以前的錯誤。此外,數據可以可視化,以做出有用的決策。
優勢
- 可以完全理解業務目標</李>
- 學習數字背后的含義</李>
- 分析以前失敗的根本原因</李>
- 使用易于理解的語言洞察未來結果</李>
- 有助于做出完美的決策</李>
先決條件
使用它的工具沒有先決條件。掌握Java或Python等編程語言的基本知識會有所幫助。了解數據庫如何工作和原始查詢就足夠了。還有其他高級語言,如Spark、Pig等,易于學習和使用。用戶應該在技術上合理地使用這些工具來獲得所需的輸出。
為什么要用它
它用于改進應用程序和服務,以提供更好的結果。可以衍生出各種經濟高效的解決方案。隨著環境的快速變化,了解客戶需求至關重要。
范圍
數據永遠不會過時,而且隨著尖端技術的發展,數據正以指數級增長。這一領域對專業人士有著巨大的需求。它正在演變,具有巨大的增長潛力。分析人員通過正確使用這些技術成為公司的決策者。
需要
如今,數據以不同的形式出現。由于實施成本和缺乏專業人員,許多分析解決方案在過去不可能實現。這樣,我們就能夠在一個時間間隔內對機器數據執行復雜的算法。它們有許多實時用例,比如欺詐檢測、全球平臺上的目標受眾、網絡廣告等。
目標受眾
利用其組件實現以下目標的組織:
- 預測客戶的未來趨勢和行為模式</李>
- 以有用的方式分析、理解和展示數據</李>
- 跟上競爭對手并在市場中保持相關性</李>
- 做出強有力的決定</李>
總結——什么是大數據
隨著需求和競爭的增長,專業人士保持更新至關重要。通過有效地利用個人和組織可以從多個方面獲益。分析師們對這個行業有了更好的了解,并將其傳達給了工人們。決策可以根據報告做出,而不是依靠猜測和直覺。











