
什么是kafka?
LinkedIn開發(fā)的用于處理實(shí)時(shí)數(shù)據(jù)的開源軟件平臺(tái)稱為Kafka。它發(fā)布和訂閱記錄流,也用于容錯(cuò)存儲(chǔ)。這些應(yīng)用程序旨在處理時(shí)間和使用記錄。不同服務(wù)器的日志分區(qū)在 Kafka 中進(jìn)行復(fù)制。它存儲(chǔ)、讀取和分析開發(fā)人員和用戶貢獻(xiàn)編碼更新的流數(shù)據(jù)。它用于消息傳遞、網(wǎng)站活動(dòng)跟蹤、日志聚合和提交日志。它可以用作數(shù)據(jù)庫,但它不具備數(shù)據(jù)模型或索引。

Apache Kafka 是一種分布式數(shù)據(jù)存儲(chǔ),經(jīng)過優(yōu)化以實(shí)時(shí)提取和處理流數(shù)據(jù)。流數(shù)據(jù)是指由數(shù)千個(gè)數(shù)據(jù)源持續(xù)生成的數(shù)據(jù),通常可同時(shí)發(fā)送數(shù)據(jù)記錄。流平臺(tái)需要處理這些持續(xù)流入的數(shù)據(jù),按照順序逐步處理。
Kafka 為其用戶提供三項(xiàng)主要功能:
發(fā)布和訂閱記錄流
按照記錄的生成順序高效地存儲(chǔ)記錄流
實(shí)時(shí)處理記錄流
Kafka 主要用于構(gòu)建適應(yīng)數(shù)據(jù)流的實(shí)時(shí)流數(shù)據(jù)管道和應(yīng)用程序。它結(jié)合了消息收發(fā)、存儲(chǔ)和流處理功能,能夠存儲(chǔ)歷史和實(shí)時(shí)數(shù)據(jù)。
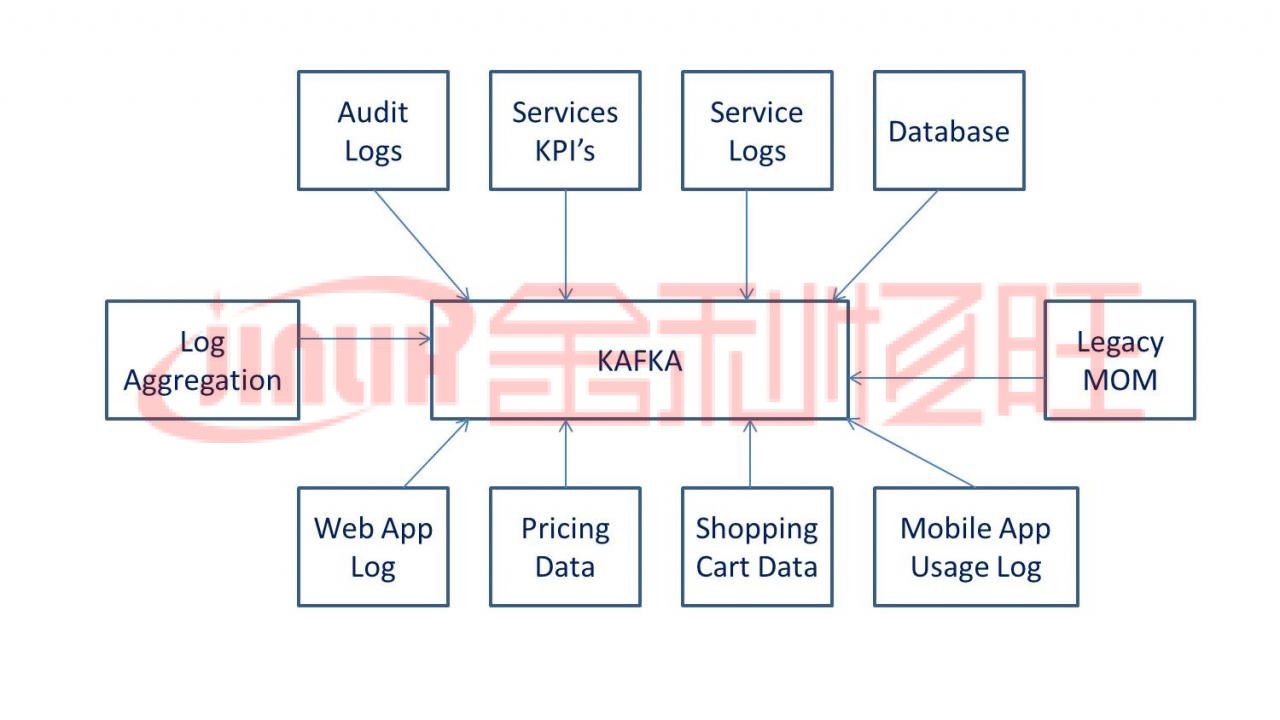
為什么使用 Kafka?
Kafka 用于構(gòu)建實(shí)時(shí)流數(shù)據(jù)管道和實(shí)時(shí)流應(yīng)用程序。數(shù)據(jù)管道在不同系統(tǒng)之間可靠處理和移動(dòng)數(shù)據(jù),而流應(yīng)用程序是消耗數(shù)據(jù)流的應(yīng)用程序。例如,如果您要?jiǎng)?chuàng)建獲取用戶活動(dòng)數(shù)據(jù)的數(shù)據(jù)管道以實(shí)時(shí)追蹤人們?nèi)绾问褂媚木W(wǎng)站,Kafka 將可在使支持?jǐn)?shù)據(jù)管道的應(yīng)用程序完成讀取操作的同時(shí),用于提取和存儲(chǔ)流數(shù)據(jù)。Kafka 還經(jīng)常用作消息代理解決方案,充當(dāng)平臺(tái)來處理和調(diào)解兩個(gè)應(yīng)用程序之間的通信。
了解kafka
它的增長呈指數(shù)級(jí)增長。讓我們看看一些事實(shí)和統(tǒng)計(jì)數(shù)據(jù),以更好地強(qiáng)調(diào)我們的想法。它享有全球超過三分之一的財(cái)富 500 強(qiáng)企業(yè)的首選。這種分布由旅游公司、電信巨頭、銀行和其他幾家公司共享。LinkedIn、Microsoft 和 Netflix 每天使用 Kafka 處理四個(gè)逗號(hào)的消息(幾乎等于 1,000,000,000,000)。
它用于實(shí)時(shí)數(shù)據(jù)流、收集大數(shù)據(jù)或進(jìn)行實(shí)時(shí)分析(或兩者兼而有之)。它與內(nèi)存中的微服務(wù)一起使用以提供持久性,并可用于將事件提供給 CEP(復(fù)雜事件流系統(tǒng))和 IoT/IFTTT 式自動(dòng)化系統(tǒng)。
Kafka 的工作原理
Kafka 結(jié)合了兩種消息收發(fā)模型、列隊(duì)和發(fā)布-訂閱,以向客戶提供其各自的主要優(yōu)勢(shì)。通過列隊(duì)可以跨多個(gè)使用器實(shí)例分發(fā)數(shù)據(jù)處理,因此具有很高的可擴(kuò)展性。但是,傳統(tǒng)隊(duì)列不支持多訂閱者。發(fā)布-訂閱方法支持多訂閱者,但是由于每條消息傳送給每個(gè)訂閱者,因此無法用于跨多個(gè)工作進(jìn)程發(fā)布工作。Kafka uses 使用分區(qū)日志模型將這兩種解決方案融合在一起。日志是一種有序的記錄,這些日志分成區(qū)段或分區(qū),分別對(duì)應(yīng)不同的訂閱者。這意味著,同一個(gè)主題可有多個(gè)訂閱者,分別有各自的分區(qū)以獲得更高的可擴(kuò)展性。最后,Kafka 的模型帶來可重放性,允許多個(gè)相互獨(dú)立的應(yīng)用程序從數(shù)據(jù)流執(zhí)行讀取以便按自己的速率獨(dú)立地工作。
列隊(duì)

發(fā)布-訂閱

kafka為什么那么快呢?
由簡單驅(qū)動(dòng)將是定義性能的正確方法。從它的設(shè)置和使用中很容易弄清楚 Kafka 是如何如此輕松地工作的。這種提高的行為性能致力于其穩(wěn)定性,提供可靠的持久性,以及靈活的內(nèi)置發(fā)布或訂閱或隊(duì)列維護(hù)功能。如果您需要處理 N 數(shù)量的客戶端組,如果您必須在市場上展示強(qiáng)大的復(fù)制,以向您的客戶提供一致的方法(即 Kafka 主題分區(qū)),那么這一點(diǎn)至關(guān)重要。Kafka 使其與競爭對(duì)手區(qū)分開來的關(guān)鍵行為是它與具有數(shù)據(jù)流的系統(tǒng)的兼容性——它的過程使這些系統(tǒng)能夠聚合、轉(zhuǎn)換和加載其他存儲(chǔ)以方便工作。“如果kafka很慢,上述所有事實(shí)都是不可能的”。
隨著 Kafka 工作的進(jìn)一步簡化,我們必須進(jìn)入“操作系統(tǒng)級(jí)別”。
讓我們看看 Kafka 在操作系統(tǒng)級(jí)別是如何工作的:
- 它依靠操作系統(tǒng)內(nèi)核來更快地移動(dòng)數(shù)據(jù),并根據(jù)零拷貝原理工作。
- 它允許將數(shù)據(jù)記錄批處理成塊,這些塊可以從文件系統(tǒng)(又名 Kafka 主題日志)中看到給消費(fèi)者。
- 批處理數(shù)據(jù)的功能提供了有效的數(shù)據(jù)壓縮和 I/O 延遲減少。
- 它具有通過分片水平擴(kuò)展的能力。它可以將標(biāo)題日志分成數(shù)百到數(shù)千個(gè)分區(qū)。這使它能夠輕松處理大量工作量。
Kafka 應(yīng)用概述
IT 行業(yè)的熱門領(lǐng)域之一是大數(shù)據(jù)。該公司處理大量客戶數(shù)據(jù)并獲得有用的見解,以幫助他們的業(yè)務(wù)并為客戶提供更好的服務(wù)。挑戰(zhàn)之一是處理這些大量數(shù)據(jù)并將其從一端傳輸?shù)搅硪欢艘赃M(jìn)行分析或處理;這就是 Kafka(一種可靠的消息傳遞系統(tǒng))發(fā)揮作用的地方,它有助于實(shí)時(shí)收集和傳輸大量數(shù)據(jù)。Kafka 專為分布式高吞吐量系統(tǒng)而設(shè)計(jì),非常適合大規(guī)模消息處理應(yīng)用程序。Kafka 支持當(dāng)今許多最好的商業(yè)和工業(yè)應(yīng)用程序。需要具有強(qiáng)大技能和實(shí)踐知識(shí)的卡夫卡專業(yè)人員。
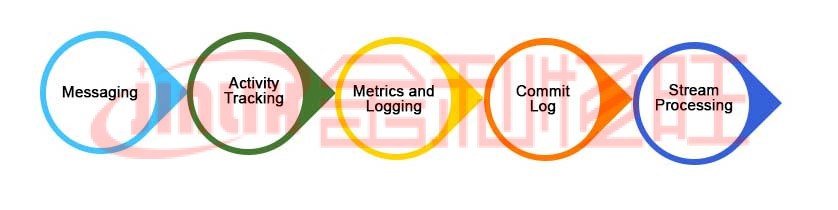
本文將了解 Kafka、它的特性、用例,并了解一些使用它的著名應(yīng)用程序。
頂級(jí) Kafka 應(yīng)用程序
本文的這一部分將看到一些流行和廣泛實(shí)現(xiàn)的用例,并看到一些 Kafka 的實(shí)際實(shí)現(xiàn)。
現(xiàn)實(shí)生活中的應(yīng)用
1. Twitter:流處理活動(dòng)
Twitter 是一個(gè)社交網(wǎng)絡(luò)平臺(tái),它使用 Storm-Kafka(一種開源流處理工具)作為其流處理基礎(chǔ)設(shè)施的一部分。反過來,輸入數(shù)據(jù)(推文)被用于聚合、轉(zhuǎn)換和豐富,以供進(jìn)一步使用或后續(xù)處理活動(dòng)。
2. LinkedIn?:流處理和度量
LinkedIn 使用 Kafka 進(jìn)行流數(shù)據(jù)和運(yùn)營指標(biāo)活動(dòng)。LinkedIn 使用 Kafka 的附加功能(例如 Newsfeed)來消費(fèi)消息并對(duì)接收到的數(shù)據(jù)進(jìn)行分析。
3. Netflix?:實(shí)時(shí)監(jiān)控和流處理
Netflix 有自己的攝取框架,可將輸入數(shù)據(jù)轉(zhuǎn)儲(chǔ)到 AWS S3 中,并使用 Hadoop 運(yùn)行視頻流分析、UI 活動(dòng)、事件以增強(qiáng)用戶體驗(yàn),并使用 Kafka 通過 API 進(jìn)行實(shí)時(shí)數(shù)據(jù)攝取。
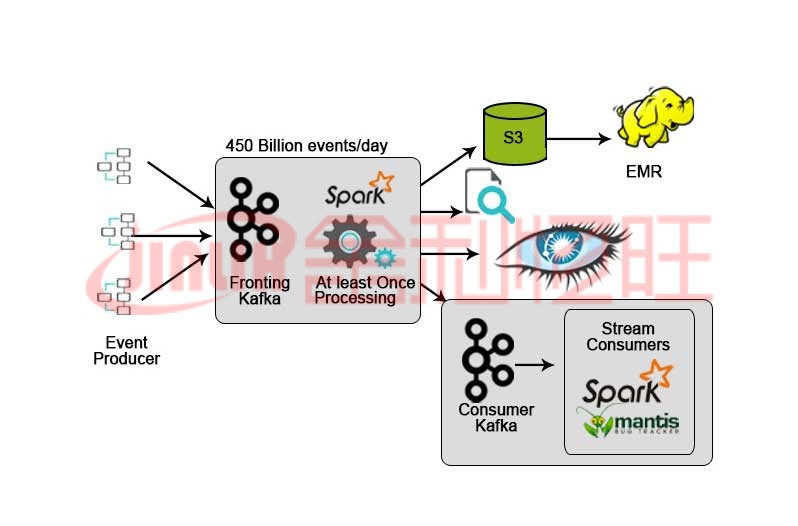
4. Hotstar?:流處理
Hotstar 推出了自己的數(shù)據(jù)管理平臺(tái)——Bifrost,其中 Kafka 用于數(shù)據(jù)流、監(jiān)控和目標(biāo)跟蹤。由于其可擴(kuò)展性、可用性和低延遲能力,Kafka 非常適合處理 Hotstar 平臺(tái)每天或在任何特殊場合(任何音樂會(huì)直播或任何現(xiàn)場體育比賽等)生成的數(shù)據(jù)的數(shù)據(jù)顯著增加。
大多數(shù)時(shí)候,Apache Kafka 被用作開發(fā)流數(shù)據(jù)架構(gòu)的構(gòu)建塊。這種架構(gòu)用于收集產(chǎn)品/服務(wù)器日志、分析點(diǎn)擊流以及從機(jī)器生成的數(shù)據(jù)中獲取信息等應(yīng)用程序中。
但與 Kafka 一起,我們需要使用額外的資源或工具將獲得的數(shù)據(jù)流轉(zhuǎn)換為有意義的數(shù)據(jù),以幫助獲得可用于數(shù)據(jù)驅(qū)動(dòng)決策的洞察力。例如,我們可能需要實(shí)時(shí)從物聯(lián)網(wǎng)設(shè)備獲得的原始數(shù)據(jù)?或從社交媒體平臺(tái)獲得的數(shù)據(jù)中生成洞察力,并進(jìn)行一些分析或處理,并將其展示給業(yè)務(wù)部門,以做出更好的決策或幫助他們改進(jìn)他們服務(wù)的表現(xiàn)。
對(duì)于這些類型的用例,我們希望將輸入數(shù)據(jù)/原始數(shù)據(jù)流式傳輸?shù)綌?shù)據(jù)湖中,以存儲(chǔ)我們的數(shù)據(jù)并確保數(shù)據(jù)質(zhì)量而不影響性能。
另一種情況,我們可能直接從 Kafka 讀取數(shù)據(jù),是當(dāng)我們需要極低的端到端延遲時(shí),例如將數(shù)據(jù)提供給實(shí)時(shí)應(yīng)用程序。
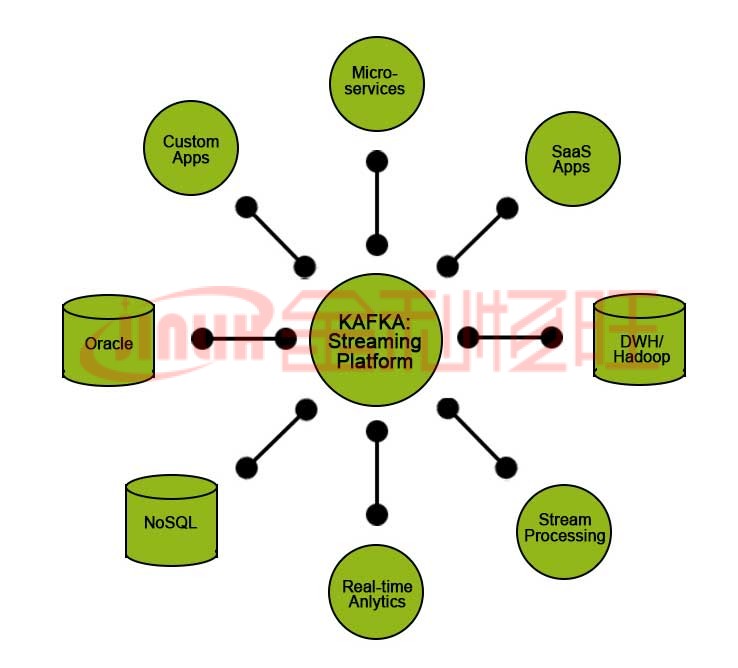
Kafka 為其用戶提供了某些功能:
- 發(fā)布和訂閱數(shù)據(jù)。
- 按有效生成的順序存儲(chǔ)數(shù)據(jù)。
- 實(shí)時(shí)/即時(shí)處理數(shù)據(jù)。
卡夫卡,大多數(shù)時(shí)候,用于:
- 實(shí)現(xiàn)在系統(tǒng)中的兩個(gè)實(shí)體之間可靠地獲取數(shù)據(jù)的動(dòng)態(tài)流數(shù)據(jù)管道。
- 實(shí)現(xiàn)轉(zhuǎn)換或操縱或處理數(shù)據(jù)流的動(dòng)態(tài)流應(yīng)用程序。
用例
以下是 Kafka 應(yīng)用程序的一些廣泛實(shí)施的用例:
1. 消息傳遞
Kafka 比 ActiveMQ、RabbitMQ 等其他傳統(tǒng)消息系統(tǒng)工作得更好。相比之下,Kafka 提供了更好的吞吐量、內(nèi)置的分區(qū)設(shè)施、復(fù)制和容錯(cuò)能力,使其成為更適合大規(guī)模處理應(yīng)用程序的消息系統(tǒng)。
2. 網(wǎng)站活動(dòng)追蹤
可以通過 Kafka 或 Kafka 跟蹤和饋送用戶活動(dòng)(頁面查看、搜索或任何操作)以進(jìn)行實(shí)時(shí)監(jiān)控或分析,以將這些類型的數(shù)據(jù)存儲(chǔ)到Hadoop 或數(shù)據(jù)倉庫中以供以后處理或操作。活動(dòng)跟蹤會(huì)生成大量數(shù)據(jù),需要將這些數(shù)據(jù)傳輸?shù)剿栉恢枚粫?huì)丟失數(shù)據(jù)。
3. 日志聚合
日志聚合是將來自應(yīng)用程序的不同服務(wù)器的物理日志文件收集/合并到單個(gè)存儲(chǔ)庫(文件服務(wù)器或 HDFS)中進(jìn)行處理的過程。與 Flume 相比,Kafka 提供了良好的性能和更低的端到端延遲。

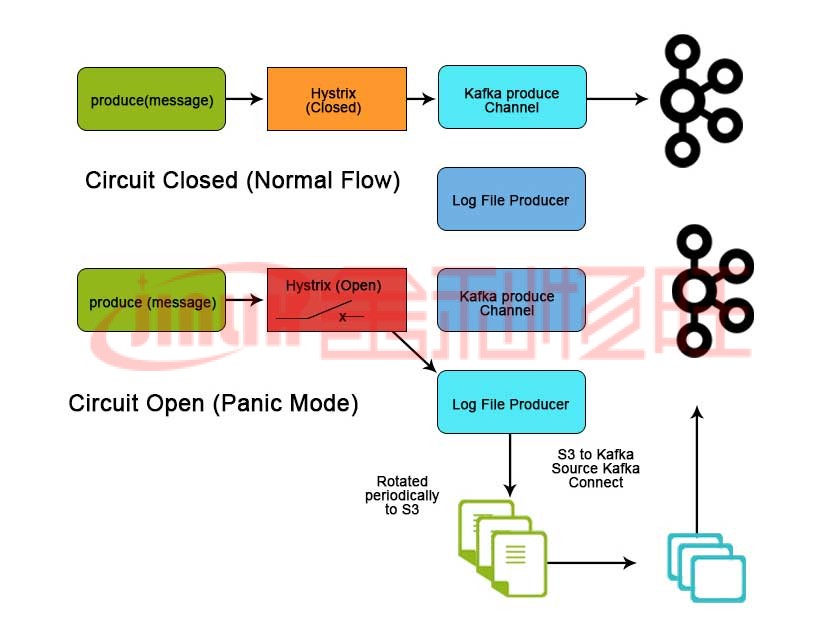
結(jié)論
Kafka 在大數(shù)據(jù)空間中被大量使用,以非常快速地?cái)z取和移動(dòng)大量數(shù)據(jù),因?yàn)樗男阅芴卣骱吞匦杂兄趯?shí)現(xiàn)可擴(kuò)展性、可靠性和可持續(xù)性。在本文中,我們討論了 Apache Kafka 的特性、用例和應(yīng)用程序,使其成為更好的流數(shù)據(jù)工具。
你可以用kafka做什么?
如果您的公司經(jīng)常處理大量數(shù)據(jù),那么您需要 Kafka。有很多公司在使用它。
- LinkedIn 使用它來跟蹤數(shù)據(jù)和運(yùn)營指標(biāo)。
- Twitter 提供流處理基礎(chǔ)設(shè)施。
從優(yōu)步到 Spotify,從高盛到思科,有很多公司。
優(yōu)點(diǎn)
以下是提到的優(yōu)點(diǎn):
- 高吞吐量:它可以在高速生成時(shí)輕松處理大量數(shù)據(jù),這是對(duì) Kafka 有利的一個(gè)特殊優(yōu)勢(shì)。該應(yīng)用程序缺乏巨大的硬件來支持每秒數(shù)千條消息的頻率的消息吞吐量。
- 低延遲:處理這種大量消息生成的低延遲。
- 容錯(cuò):這個(gè)功能很方便;它具有受集群中內(nèi)置節(jié)點(diǎn)限制的固有能力。
- 耐用:它的操作非常耐用,這也是許多跨國公司更喜歡使用 Kafka 的原因。談到操作的持久性,從長遠(yuǎn)來看,消息不會(huì)丟失。
所需技能
成為 Kafka 專業(yè)人士沒有特殊要求。
但我們強(qiáng)調(diào)了一些流和專業(yè)人士:
- 愿意在大數(shù)據(jù)流中從事職業(yè)并希望加速其職業(yè)生涯的開發(fā)人員。
- 就隊(duì)列和消息系統(tǒng)而言,測試專業(yè)人??員在 Kafka 中有很好的范圍。
- 架構(gòu)師——因?yàn)橐磺卸夹枰恍┛蚣埽疫@個(gè)框架可以不時(shí)更新。大數(shù)據(jù)架構(gòu)師會(huì)發(fā)現(xiàn) Kafka 是一項(xiàng)很好的職業(yè)投資。
- 如果有上述專業(yè)人員可以更好地管理資源,則需要項(xiàng)目經(jīng)理。因此,Kafka領(lǐng)域的管理專業(yè)人員也可以獲得更高的職位。
為什么使用kafka?
為了根據(jù)業(yè)務(wù)需要跟蹤和處理數(shù)據(jù),它在全球范圍內(nèi)都是首選。它提供了通過實(shí)時(shí)分析實(shí)時(shí)流式傳輸數(shù)據(jù)的可能性。它快速、可擴(kuò)展、耐用,并且設(shè)計(jì)為容錯(cuò)。Web 上有多個(gè)用例,您可以從中了解為什么 JMS、RabbitMQ 和 AMQP 甚至不被認(rèn)為可以使用,因?yàn)樾枰僮鞔罅亢晚憫?yīng)能力。
它具有高吞吐量、具有復(fù)制特性的可靠設(shè)置,使其成為在物聯(lián)網(wǎng)傳感器上工作的首選。
兼容性是使用它并使其在全球范圍內(nèi)接受的另一個(gè)原因。它可以輕松配置為與下面列出的應(yīng)用程序一起使用。這種組合對(duì)于許多公司發(fā)展業(yè)務(wù)和生存至關(guān)重要(因?yàn)樗梢怨?jié)省時(shí)間和金錢)。
- 水槽
- 火花流
- HBase
- Spark 用于數(shù)據(jù)的實(shí)時(shí)攝取、處理和分析。
- 它用于提供 Hadoop BigData。
范圍
它在全球范圍內(nèi)都做得很好。好吧,我們不是說這個(gè)而是統(tǒng)計(jì)數(shù)據(jù)。
kafka專業(yè)人士的薪資統(tǒng)計(jì) - PayScale
- 軟件工程師——109,825 美元
- 數(shù)據(jù)工程師——109,580 美元
- 開發(fā)人員——81,182 美元
- 高級(jí)數(shù)據(jù)工程師——127 美元,836 美元

結(jié)論
目前,kafka已經(jīng)成為實(shí)時(shí)數(shù)據(jù)分析的事實(shí)標(biāo)準(zhǔn),精度最高,以微秒為單位。我們?cè)跀?shù)據(jù)和細(xì)節(jié)方面提出了我們的見解,以支持 Kafka 技術(shù)。幾家大公司每天都在利用數(shù)據(jù);為此,他們需要專業(yè)人員來利用這些龐大的數(shù)據(jù)集。使用 Kafka,可以確保在大數(shù)據(jù)分析領(lǐng)域引領(lǐng)他們的職業(yè)生涯。











